大数据问题解决方案 模式选择与产品实现策略
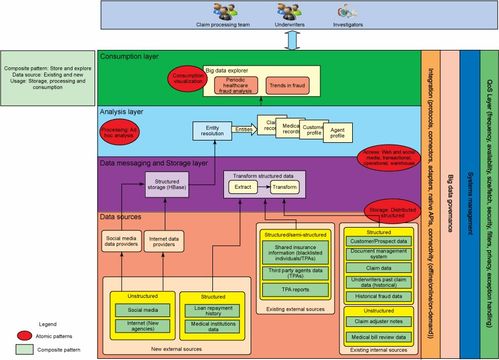
在当今数据驱动的时代,大数据问题已成为企业数字化转型的关键挑战。针对大数据问题,应用科学合理的解决方案模式并选择合适的产品,是提升计算机系统服务效率与精准度的核心环节。
一、大数据问题的主要特征与挑战
大数据问题通常表现为数据量大、数据类型多样、处理速度要求高以及价值密度低等特点。企业面临的挑战包括数据采集、存储、处理、分析和可视化等多个环节。例如,金融行业需要实时处理海量交易数据以进行风险控制,电商平台需分析用户行为数据以优化推荐系统。
二、解决方案模式的应用
1. Lambda架构与Kappa架构
Lambda架构结合批处理与流处理的优势,适用于对历史数据和实时数据均有高要求的场景。Kappa架构则简化流程,完全基于流处理,适合实时性要求极高的应用。企业可根据业务需求选择:如金融风控系统可能采用Lambda架构,而物联网实时监控可能更倾向于Kappa架构。
2. 数据湖与数据仓库结合模式
数据湖存储原始数据,支持多种数据类型;数据仓库存储结构化数据,便于分析。结合两者可实现灵活性与高效性的平衡。例如,医疗健康领域可将患者影像数据存入数据湖,结构化病历数据存入数据仓库,以支持综合诊断分析。
3. 微服务与容器化部署
通过微服务架构将大数据系统分解为独立服务,结合容器化技术(如Docker和Kubernetes)提升部署弹性和资源利用率。这种模式特别适合需要快速迭代和扩展的互联网服务。
三、产品选择与实现策略
- 存储层产品选型
- 分布式文件系统:HDFS适用于大规模批处理场景,如云存储备份系统。
- NoSQL数据库:MongoDB适合存储半结构化数据,Cassandra则在高写入场景中表现优异,可应用于社交媒体的用户数据管理。
- 云存储服务:AWS S3或阿里云OSS提供高可用的对象存储,适合混合云环境的数据归档。
- 处理层产品选型
- 批处理框架:Apache Spark因其内存计算优势,广泛用于数据挖掘和机器学习任务。
- 流处理框架:Apache Flink提供低延迟处理,适用于实时欺诈检测系统。
- 查询引擎:Presto或Impala支持跨数据源快速查询,适合企业级数据仓库分析。
- 管理与调度工具
- 工作流调度:Apache Airflow可编排复杂的数据管道,确保ETL流程的可靠性。
- 集群管理:Apache Ambari或Cloudera Manager简化Hadoop生态系统的运维。
四、计算机系统服务的实施建议
1. 需求分析与架构设计
首先明确业务目标,例如是降低延迟还是提高吞吐量。设计架构时需考虑可扩展性和容错性,如采用多副本存储防止数据丢失。
2. 产品集成与测试
选择兼容性强的产品组合,并通过概念验证测试性能。例如,将Kafka用于数据采集,Spark Streaming进行实时处理,最终结果存入Elasticsearch以支持快速检索。
3. 运维与优化
建立监控体系,使用Prometheus和Grafana跟踪系统指标。定期优化资源配置,如调整Spark executor内存以提升作业效率。
五、案例实践
以智慧城市交通管理系统为例:采用Lambda架构处理历史流量数据(批处理)和实时传感器数据(流处理);存储层使用HDFS和HBase;处理层采用Spark进行拥堵模式分析;通过Tableau实现可视化展示。该方案显著提升了交通调度效率。
大数据问题的解决需要模式与产品的有机结合。企业应基于具体场景选择架构模式,并搭配成熟的产品工具,同时注重系统服务的全生命周期管理,从而实现数据价值最大化并推动业务创新。
如若转载,请注明出处:http://www.wekaxs.com/product/8.html
更新时间:2026-06-19 17:16:01