基于MySQL的亚马逊智能产品评论数据分析中的数据处理与分列技术
在当今数据驱动的商业环境中,亚马逊等电商平台的智能产品评论是洞察市场趋势、产品表现和用户偏好的宝贵资源。原始的评论数据往往混杂、非结构化,直接分析难度大。本文聚焦于如何利用MySQL数据库进行高效的数据处理,特别是数据分列技术,为后续的深度分析奠定坚实基础。
一、 数据获取与初步观察
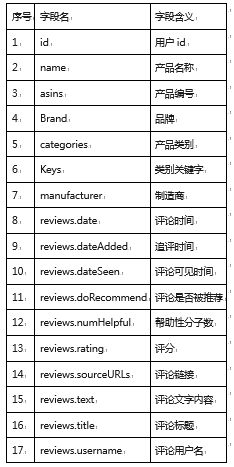
我们从公开数据集或内部渠道获取亚马逊智能产品(如智能音箱、智能家居设备等)的评论数据。原始数据通常以CSV或JSON格式存储,包含但不限于以下字段:review<em>id(评论ID)、product</em>id(产品ID)、reviewer<em>id(用户ID)、review</em>text(评论文本)、review<em>rating(评分,如1-5星)、review</em>date(评论日期)、helpful<em>votes(有用投票数)等。在导入MySQL前,需使用LOAD DATA INFILE或图形化工具(如MySQL Workbench)将数据载入预定结构的表中。初步使用DESCRIBE table</em>name;和SELECT * FROM table_name LIMIT 10;等SQL命令观察数据结构、类型及样本,识别潜在问题,如缺失值、异常格式或冗余字段。
二、 核心数据处理:分列与字段解析
“分列”是数据处理中的关键步骤,旨在将复合字段拆分为更原子化、易于分析的独立列。在亚马逊评论场景中,常见分列需求包括:
1. 时间字段解析:原始review<em>date可能为“2023-05-15 14:30:00”格式。我们可以使用MySQL的日期时间函数进行分列,提取年、月、日、小时等独立维度,便于按时间趋势分析。
`sql
ALTER TABLE reviews ADD COLUMN reviewyear INT, ADD COLUMN reviewmonth INT;
UPDATE reviews SET reviewyear = YEAR(reviewdate), reviewmonth = MONTH(review_date);
`
2. 评论文本特征提取:review<em>text是核心非结构化数据。虽然深度文本分析(如情感分析)通常需借助Python等工具,但可在MySQL中执行基础分列:
- 长度特征:计算评论字数或字符数,作为详尽度的指标。
`sql
ALTER TABLE reviews ADD COLUMN textlength INT;
UPDATE reviews SET textlength = CHARLENGTH(review_text);
`
- 关键词标志:使用LIKE或REGEXP创建布尔列,标记评论是否包含特定关键词(如“电池寿命”、“易用性”、“bug”)。
`sql
ALTER TABLE reviews ADD COLUMN mentionsbattery BOOLEAN DEFAULT FALSE;
UPDATE reviews SET mentionsbattery = TRUE WHERE reviewtext LIKE '%电池%' OR reviewtext LIKE '%battery%';
`
3. 复合评分解析:有时原始评分可能包含在文本中,或需从其他复合字段(如“5 out of 5 stars”)提取。可使用字符串函数(如SUBSTRING<em>INDEX, REGEXP</em>SUBSTR)进行分列。
4. 用户行为分列:helpful<em>votes字段可能隐含“总投票数”和“认为有用的票数”。若原始数据为“15/20”格式,则可分列为两列:
`sql
ALTER TABLE reviews ADD COLUMN helpfulcount INT, ADD COLUMN totalvotes INT;
UPDATE reviews
SET helpfulcount = CAST(SUBSTRINGINDEX(helpfulvotes, '/', 1) AS UNSIGNED),
totalvotes = CAST(SUBSTRINGINDEX(helpfulvotes, '/', -1) AS UNSIGNED)
WHERE helpfulvotes LIKE '%/%';
`
三、 数据清洗与质量提升
分列前后,需进行全面的数据清洗:
- 处理缺失值:使用
COALESCE()函数为关键字段设置默认值,或根据业务逻辑决定删除/插补。 - 标准化格式:确保分列后的数据格式统一,如日期为
DATE类型,数值为INT/DECIMAL类型。 - 去重与一致性检查:通过
DISTINCT、GROUP BY结合HAVING子句识别并处理重复评论或异常记录。 - 创建衍生列:基于分列后的基础字段,计算衍生指标,如
helpfulness<em>ratio(有用率 = helpfulcount / total_votes),为分析提供更多维度。
四、 数据整合与索引优化
完成分列与清洗后,数据表结构更加清晰。此时,应:
- 重构表结构:考虑将大表规范化,例如将频繁分析的字段(如产品信息、用户 demographics 如果可用)拆分到关联表,通过
JOIN查询,提高灵活性。 - 添加索引:在分列后常用于查询和连接的列(如
product<em>id,review</em>year,review_rating)上创建索引,显著提升后续分析查询的性能。
五、
通过MySQL强大的字符串函数、日期时间函数和DML(数据操作语言)能力,我们可以对亚马逊智能产品评论数据执行有效的分列处理,将原始非结构化或半结构化数据转化为整洁、多维度、适于分析的结构化格式。这一数据处理阶段是后续进行趋势分析、产品对比、用户情感挖掘和预测建模的基石。值得注意的是,对于极复杂的文本分析,可能需要结合外部工具,但MySQL在数据预处理和基础特征工程方面的效率与便捷性,使其成为数据分析流程中不可或缺的一环。经过精心处理的数据集将赋能企业做出更智能的产品改进与营销决策。
如若转载,请注明出处:http://www.wekaxs.com/product/7.html
更新时间:2026-06-19 08:10:52